Section 4 · The dense vs MoE story
Why the smartest model is also the slowest
In April 2026, Qwen 3.6 27B (dense) beats every MoE peer on benchmarks — including an 80B MoE. Running locally, it's also dead last on generation speed. Both facts have the same cause: Qwen 3.6 activates all 27B parameters for every token. MoE peers activate ~3B.
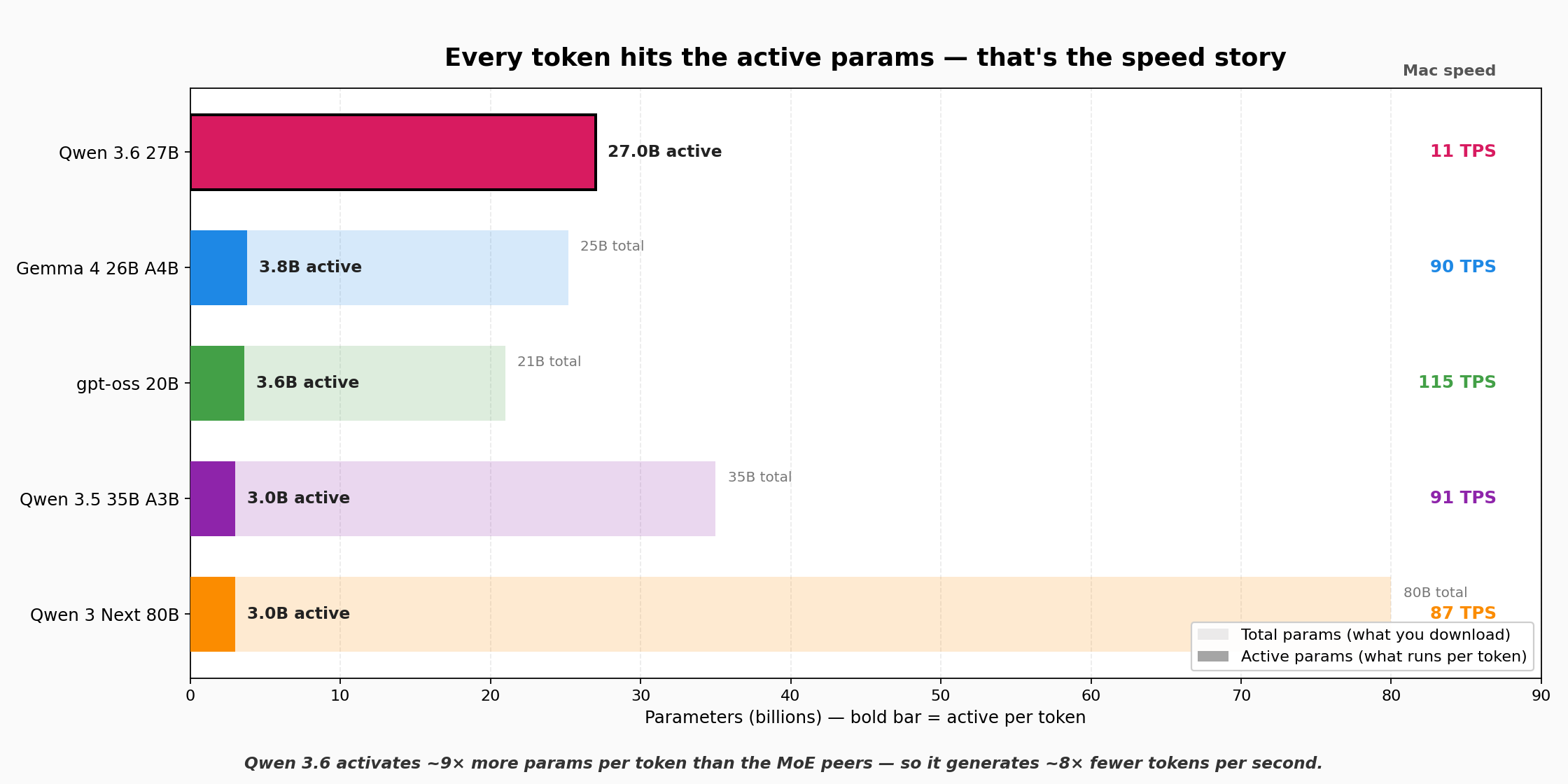
Dense pays per token in latency to deliver per-token intelligence. MoE pays in total RAM footprint to deliver per-token speed. A 128GB-class box handles either architecture comfortably — which is why consumer hardware is surprisingly future-proof for local inference.